
Gestión centralizada de logs
1. Introducción
El siguiente artículo desarrolla el tema de la gestión centralizada de logs. En primer lugar, se explica de forma general que es un log, los tipos y formatos que existen, los datos que se recogen, así como su seguridad. Por otro lado, se profundiza en la centralización de los logs, en la creación de un sistema centralizado y el ejemplo concreto de posible implantación para un colegio. Por último, se tratan diferentes usos de la gestión centralizada en las herramientas de análisis y su futuro.
2. El log
2.1. Qué es un log
En informática o computación, un log es el lugar en el que se almacenan eventos que suceden en los sistemas operativos, servidores u otros tipos de software y que afectan a un proceso particular. Estos datos son registrados, normalmente, en ficheros de texto plano o en otros como XML/JSON, aunque también pueden guardarse en bases de datos.
En la siguiente imagen puede verse un ejemplo el log generado por el servidor web Apache:

2.2. Tipos de log
En primer lugar, existen los logs que recogen los datos de las aplicaciones informáticas. Los registros de una aplicación son los encargados de almacenar las operaciones que suceden durante su funcionamiento y forma parte de la propia lógica u operativa. Del mismo modo, recogen la actividad que realizan los usuarios (login/logout, origen, tiempo de actividad, acciones, conexiones, etc.). En este grupo podemos encontrar los logs de una aplicación de escritorio como Word, las aplicaciones web desarrolladas a medida para la compañía o los que se generan por el software de un servicio web.
Por otro lado, tenemos los que almacenan los eventos del sistema. En este caso los logs se generan cronológicamente con los sucesos que se van produciendo en los componentes de dicho sistema. En este caso, un ejemplo es el de los sistemas UNIX y similares, que utilizan el programa syslogd[1] para registrar las actividades del sistema operativo.
Por último, también podemos encontrar los logs de transacciones que son los utilizados, por ejemplo, por los sistemas de bases de datos con el objeto de poder disponer de un histórico de las acciones y recuperarse ante errores, inconsistencia de datos u otros acontecimientos que van más allá del normal funcionamiento. Por ejemplo, SQL Server utiliza este tipo de logs para su funcionamiento, sin este registro no es posible ponerlo en marcha y no puede soportar el estándar ACID[2] (Atomicidad, Consistencia, Aislamiento y Durabilidad).
2.3. Formatos y estándares
2.3.1. Formatos
El formato típico de fichero log que más se ha extendido es el que contiene un registro por línea y en el que, por cada línea, contiene los datos separados por espacios. Este tipo de formato es muy interesante a la hora de generar ficheros que ocupen menos espacio en disco, dado que no contiene caracteres adicionales para su ordenación o comprensión como separadores, etiquetas, llaves, etc. El siguiente es un ejemplo:
12:23:10 [INF] Service «loyalty-card-printer» starting up on host 8fd342hkg22u
12:23:11 [INF] Listening on http://8fd342hkg22u.example.com:1234
12:23:20 [INF] Card replacement request received for customer-109972
12:40:55 [INF] Card replacement request received for customer-98048
Este formato, sin embargo, dificulta la labor posterior de análisis o parseado (del inglés, parsing), así como su asociación directa con los ficheros logs de otros sistemas o aplicaciones, dado que no contienen la misma estructura.
Por otro lado, debido a la popularidad de formatos de intercambio de datos como JSON o XML, surge la alternativa de almacenamiento de registro de eventos directamente en estos formatos, con la ventaja de poder ser interpretados fácilmente por aplicaciones de lectura de estos estándares y conectarlos a las aplicaciones de análisis. El siguiente ejemplo contiene una estructura basada en JSON:
{
"time": "2016-06-01T02:23:10Z",
"level": "INF",
"template": " Card replacement request received for {CustomerId}",
"properties": {
"customerId": " customer-109972"
}
}
2.3.2. Estándares
Según el entorno o el tipo de log que vaya a generarse, existen varios estándares que pueden utilizarse para facilitar la intercomunicación de elementos o para facilitar su posterior utilización. Algunos de los más populares son Syslog, para sistemas informáticos, o Common Log Format (CLF) y Extended Log Format (ELF) para los servidores web.
Syslog
Permite la separación del software que genera mensajes, el sistema que los almacena y el software que los informa y analiza. Cada mensaje está etiquetado con un código de instalación, que indica el tipo de software que genera el mensaje, y se le asigna un nivel de gravedad.
Los diseñadores de sistemas informáticos pueden usar syslog para la gestión del sistema y la auditoría de seguridad, así como mensajes generales de información, análisis y depuración. Una amplia variedad de dispositivos, como impresoras, enrutadores y receptores de mensajes en muchas plataformas utilizan el estándar syslog. Esto permite la consolidación de datos de registro de diferentes tipos de sistemas en un repositorio central. Existen implementaciones de syslog para muchos sistemas operativos.
Common Log Format (CLF) y Extended Log Format (ELF)
CLF y ELF son formatos de archivo de texto estandarizado utilizado por muchos servidores web para generar registros, la diferencie entre ambos es que ELF puede contener más información. Estos estándares permiten su posterior lectura y análisis por gran cantidad de programas de análisis como, por ejemplo, Webalizer, Analog o awstats.
2.4. Qué datos se almacenan en un log
Como veremos más adelante, el análisis de los logs es fundamental para cuestiones como el mantenimiento y la mejora de los sistemas digitales, la prevención y resolución de delitos informáticos, así como para determinar patrones de comportamiento en el software informático. Por lo tanto, los datos que debemos almacenar son fundamentales si queremos, después, poder analizarlos y obtener información válida con la que tomar decisiones que permitan lograr esos objetivos. Aunque cada fichero de registro puede ser diferente, podemos encontrarnos con los siguientes datos:
- Fecha y hora (teniendo especial cuidado con las zonas horarias).
- Tipo: error, alerta, debug, etc.
- Dirección del dispositivo (puede ser una IP).
- Código (código único del suceso).
- Mensaje (una descripción ampliada del suceso).
- Usuario (usuario del sistema o la aplicación).
- Contexto (fichero, página o parte de la aplicación que ha generado el registro).
Estos registros deben estar especialmente preparados para su lectura y procesamiento, y, por lo tanto, se les establecen datos como la fecha en la que ha sucedido o categorización para establecer el tipo de suceso: error, alerta, debug (depuración), etc.
2.5. La seguridad de los logs y la consistencia de los datos
El registro log es fundamental, por ejemplo, para esclarecer un caso de robo de información, ataque informático o alertar de un mal funcionamiento de un sistema digital, por lo tanto, mantener seguros los logs y que sus datos sean correctos es fundamental en cualquier sistema profesional; de lo contrario, podríamos estar generando un registro que, finalmente, no sería confiable para su posterior uso.
En primer lugar, como para cualquier otro sistema o componente expuesto a posibles ataques o dificultades generadas por un uso indebido, deben estar debidamente protegidos. Para ello, es recomendable seguir las recomendaciones habituales:
- El hardware debe estar debidamente protegido.
- Se debe contar con software de protección: antivirus, antimalware, firewall, etc.
- Los accesos remotos al lugar de almacenamiento de logs deben ser controlados.
- Deben realizarse copias de seguridad de los registros log.
Por otro lado, debe garantizarse que los datos sean en todo momento correctos y que no hayan sido mal formados o manipulados durante todo el ciclo de uso, desde su generación hasta su posterior análisis. En ese sentido, son fundamentales las propias verificaciones de la correcta generación, por ejemplo, validar que el log es generado con todos los campos esperados y que estos campos son correctos, y que no contiene datos inesperados como una fecha del año 1970 en un fichero de reciente creación.
Por último, es muy importante controlar el crecimiento de los ficheros de log, dado que, si no se cuenta con una funcionalidad de este tipo, el log continuará creciendo en tamaño según se vayan añadiendo nuevos eventos y llegará un momento en el que pueda hacer que ocupe un gran espacio en disco o que se convierta en un fichero que no pueda ser manipulable. En ese sentido, los sistemas de log cuentan ya con una herramienta conocida como Logrotate que permite configurar el número de ficheros que se desean almacenar, así como su tamaño. Por ejemplo, una configuración típica puede ser la que guarda datos en el fichero hasta llegar a 10MB y que, posteriormente, los almacena en un fichero comprimido. Además, se puede determinar que únicamente almacene hasta 20 o 30 ficheros comprimidos y que, a partir de ahí, empiece a eliminar los más antiguos.
3. La centralización de logs
3.1. Qué es y cuál es su objetivo
La centralización de logs o agregación de registros es el paso previo para la gestión centralizada en el que los registros son importados de diferentes fuentes a través de la infraestructura informática y se recopilan en una única ubicación central. Mediante el uso de ciertos cargadores de ficheros o datos, se envían los registros desde un origen como aplicaciones, contenedores, bases de datos o cualquier otro sistema y los registros se agregan y almacenan en una ubicación central.
Los datos almacenados en este lugar deben disponer de una estructura común y conocida para su posterior lectura y análisis en condiciones adecuadas de rapidez y eficacia. Por tanto, la labor de centralizar los logs no acaba únicamente con el movimiento de los datos a un lugar central, si no que debe ser capaz de realizar una transformación con los que normalizar los datos.
Finalmente, lo normal es que todos estos datos centralizados queden indexados en una base común, para ello se utilizan herramientas como Elasticsearch[3] o Apache Solr[4], que son las más conocidas. Los logs se almacenan y archivan, lo que facilita la búsqueda y el análisis de sus datos. Además, al tener todos los registros en un solo lugar, permitirá acceder a ellos a través de una única interfaz de usuario sin la molestia de conectarse a máquinas y ejecutar comandos como grep. Por tanto, esta es la razón por la que la administración central de logs es tan poderosa y hace que la vida de los informáticos sea mucho más fácil.
3.2. Cómo construir un gestor centralizado de logs: un caso práctico
En primer lugar, vamos a analizar las necesidades generales que podríamos tener a la hora de montar un sistema centralizado de logs y, a continuación, veremos un caso práctico.
3.2.1. Cómo construir un gestor centralizado
A la hora de abordar este tipo de trabajos podemos encontrarnos múltiples situaciones, desde las más básicas que tratarían casos simples como la de un trabajador autónomo que únicamente quiere analizar sus logs, hasta las de multinacionales en las que su negocio se centra en Internet y necesitan de sistemas complejos para poder monitorizar diferentes subsistemas.
Vamos a tratar de proponer una arquitectura que cubra las necesidades más típicas de forma profesional y para ello, en primer lugar, vamos a ver los componentes que tendría nuestro sistema y que serían los siguientes: cargador o shipper, broker, log indexer, almacenamiento y búsqueda, y analizador y alertas.
Cargador o shipper:
Tiene la función de recuperar los datos y logs que se encuentran en las diferentes máquinas o servidores para que puedan ser agrupados en un mismo lugar para su posterior transformación. El cargador puede recuperar los ficheros logs o directamente los datos o eventos que se producen. Además, puede ser interesante que el shipper envíe primero los datos a una cola o broker de mensajería para evitar un colapso en la transferencia de datos.
Una herramienta muy interesante que podemos utilizar es Beats[5], de la familia Elastic. Cuenta con diferentes módulos como Filebeat, Metricbeat o Packetbeat, que nos va a permitir no solo recuperar datos de un lugar determinado, si no que están preparados para funcionalidades muy concretas como la lectura de ficheros de logs de aplicaciones conocidas como Nginx o Springboot, o leer los paquetes que circulan por un determinado protocolo de red.
Broker:
El broker es uno de los componentes que no tiene porque ser obligatorio y que la necesidad de integrarlo va a depender del tamaño y volumen de datos que vaya a manejar el sistema. En el caso de que vaya a haber un intercambio grande de datos y se quiera garantizar el 100 % de la entrega, lo normal es contar con una herramienta que realice una gestión avanzada de la entrega de datos. Con ese objetivo, pueden incorporarse al sistema herramientas como Redis PUB/SUB [6] o Apache ActiveMQ[7]. Estás aplicaciones están basadas en el patrón Publicación-subscripción[8] y realizan una gestión avanzada de cola con los datos que reciben para asegurar que son entregados al destinatario final; pudiendo hacerlo persistente en una base de datos o fichero. De esta forma, si, por ejemplo, falla una entrega, el propio sistema se encarga de recuperarlo y entregarlo cuando sea posible.
Log indexer:
Es el encargado de procesar los mensajes para tratarlos y transformarlos en datos que puedan ser almacenados e indexados para su posterior análisis. Una herramienta avanzada para la administración de los logs puede utilizarse para recolectar, parsear y guardar los registros para futuras búsquedas.
Una de las herramientas de interés que podemos utilizar es Logstash[9]. La aplicación se encuentra basada en jRuby y como se ejecuta mediante JVM puede ser lanzada en cualquier Sistema Operativo que ejecute JVM (Linux, Mac OS X, Windows). Funciona con las entradas, códecs, filtros y salida; donde las entradas son las fuentes de datos. Los códecs esencialmente convierten un formato de entrada en un formato aceptado por Logstash, así como también transforman del formato de Logstash al formato deseado de salida. Estos son utilizados comúnmente si la fuente de datos no es una línea de texto plano. Los filtros son acciones que se utilizan para procesar en los eventos y permiten modificarlos o eliminar eventos tras ser procesados. Finalmente, las salidas son los destinos donde los datos procesados deben ser derivados.
Por otro lado, también existen otras alternativas a Logstash como por ejemplo Fluentd[10] o Graylog[11]. Todas son interesantes, aunque se diferencian en cuestiones como el uso que hacen de los recursos, su grado de especialización en un determinado tipo de registros o si puede integrarse de forma nativa dentro de un ecosistema de herramientas más amplio como Elastic.
Almacenamiento y búsqueda:
Contar con un almacenamiento avanzado y preparado para la realización de búsquedas es fundamental para el posterior análisis de datos. Algunas de las herramientas que hemos visto ya cuentan con este componente, sin embargo, existen aplicaciones que pueden ejecutarse con esta finalidad, como es el caso de Elasticsearch o Apache Solr.
Elasticsearch nos permite indexar un gran volumen de datos y nos sirve de almacenamiento centralizado para todos nuestros logs e indexarlos para que su búsqueda posterior se ejecute a gran velocidad. Esta potente herramienta cuenta con múltiples posibilidades de integración[12] con herramientas de terceros como Business Intelligence (BI) o Big Data así como implementar integraciones mediante su API Rest.
Por otro lado, Apache Solr, es un potente motor de búsqueda de código abierto basado en la biblioteca Java del proyecto Lucene, que cuenta también con APIs en XML/HTTP y JSON, resaltado de resultados, búsqueda por facetas, caché y una interfaz para su administración. Aunque nació unos años antes que Elasticsearch, su popularidad y uso no ha crecido al mismo nivel. No obstante, es un proyecto muy robusto, que cuenta con una gran comunidad activa y mucha documentación.
Analizador:
Por último, necesitamos disponer de una herramienta que permita convertir todos los datos que hemos almacenado en información válida. Para ello, necesitamos contar con una aplicación que nos permita la visualización avanzada de datos, generación de alertas, detección de anomalías o futuras demandas con técnicas de Machine Learning, análisis por ubicación, generación de grafos y redes, etc.
En el marcado existen varias herramientas para el análisis de grandes volúmenes de datos y, a continuación, vamos a ver algunas de las más conocidas e interesantes para la gestión centralizada de logs:
Kibana:
Kibana[13] es un panel de visualización de datos de código abierto para Elasticsearch. Proporciona capacidades de visualización sobre el contenido indexado en un clúster Elasticsearch. Pueden crearse gráficos de barras, líneas y dispersión o gráficos circulares y mapas, sobre grandes volúmenes de datos. Del mismo modo, también proporciona una herramienta de presentación, denominada Canvas, que permite a los usuarios crear diapositivas que extraen datos en vivo directamente de Elasticsearch.
Entre sus características principales destacan:
- Generación de gráficos drag-and-drop.
- Exploración y visualización avanzada: gráficos, tablas, etc.
- Embeber, importar/exportar, compartir elementos, etc.
- Machine learning y BI. Detección de anomalías.
- Creación de alertas por email o en diferentes plataformas[14].
- Entorno y comunicaciones segurizadas.
Descarga e instalación de Kibana: https://www.elastic.co/es/downloads/kibana
Grafana:
Grafana[15] es un software libre basado en licencia de Apache 2 que permite la visualización y el formato de datos métricos. Permite crear cuadros de mando y gráficos a partir de múltiples fuentes, incluidas bases de datos de series de tiempo como Graphite, InfluxDB y OpenTSDB. Comenzó como un componente de Kibana y que luego le fue realizado una bifurcación.
Entre sus características principales destacan:
- Dispone de dashboboards o tableros compartidos por su comunidad[16].
- Es multiplataforma sin ninguna dependencia y se puede implantar con Docker.
- Permite la posibilidad compartir los cuadros de mando.
- Tiene una funcionalidad de usuarios basada en roles de organización.
- Dispone de sistema de alertas.
Descarga e instalación de Grafana: https://grafana.com/grafana/download
Cacti:
Cacti[17] es una completa solución para la generación de gráficos en red, diseñada para aprovechar el poder de almacenamiento y la funcionalidad para gráficas que poseen las aplicaciones RRDtool (BD que maneja Planificación Round-robin). Esta herramienta está desarrollada en PHP.
Entre sus características principales destacan:
- Dispone de plantillas de gráficos avanzadas.
- Tiene una interfaz de usuario fácil de usar.
Descarga e instalación de Cacti: https://www.cacti.net/download_cacti.php
Splunk:
Splunk[18] es un software para buscar, monitorizar y analizar macrodatos generados por máquinas de aplicaciones, sistemas e infraestructura IT a través de una interfaz web. Del mismo modo, captura, indexa y correlaciona en tiempo real, almacenándolo todo en un repositorio donde busca para generar gráficos, alertas y paneles fácilmente definibles por el usuario.
Entre sus características principales destacan:
- Generación de gráficos avanzados.
- Monitorización y alertas.
- Aplicaciones para funciones específicas.
- Especialmente pensado para Big Data.
Descarga e instalación de Splunk: https://www.splunk.com/en_us/download.html
DataDog:
Datadog[19] es un servicio de monitorización para aplicaciones en la nube, que proporciona monitorización de servidores, bases de datos, herramientas y servicios, a través de una plataforma de análisis de datos basada en SaaS (Software como Servicio). Por tanto, ayuda a los desarrolladores y equipos de operaciones a ver su infraestructura completa (nube, servidores, aplicaciones, servicios, métricas y más) en un solo lugar.
Entre sus características principales destacan:
- Es una plataforma SaaS y Cloud.
- Dispone de gráficos y paneles interactivos.
- Generación de alertas por correo electrónico, PagerDuty, Slack y otros canales.
- Dispone de herramientas de automatización.
- Integración con terceros.
Contratación de Splunk en la nube: https://www.datadoghq.com/
La arquitectura
Como es lógico, todos estos componentes deben estar debidamente configurados y orquestados para disponer de la salida de información necesaria en el tiempo deseado. Para ello, debe generarse un engranaje como el siguiente que cumpla con la siguiente arquitectura:
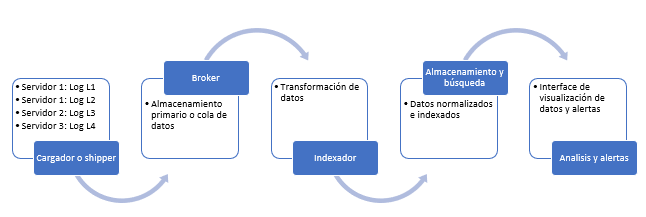
Como observamos en la imagen, partimos de varias fuentes de datos en diferentes servidores, por lo tanto, lo primero que debe hacer el cargador es ocuparse de recuperar esos datos y almacenarlos o encolarlos con la periodicidad que se estime necesaria. El siguiente paso es la preparación de esos datos para que puedan ser debidamente indexados y de eso se encarga el indexador. Una vez que esos datos están ya en indizados, la herramienta de análisis puede generar la interfaz visual con la que poder sacar información válida y generar las alertas necesarias.
3.2.2. La centralización de logs para un colegio
A continuación, partiendo de la necesidad particular de una organización, vamos a ver cómo puede construirse un sistema que permita la gestión centralizada de los logs. En este caso, se trata de un colegio que quiere implantar una herramienta única que le permita monitorizar el sistema informático y poder, así, disponer de información de cara a poder actuar en el caso de sucesos de carácter anómalo. En esta primera etapa, se va a realizar el seguimiento de los siguientes datos:
- Log de ERP: aplicación de gestión que contiene facturación, nóminas, etc.
- Log del sistema operativo del servidor local.
- Log del sistema operativo del servidor web.
- Log de la aplicación web: notas de alumnos, comunicaciones, etc.
Para poner en marcha el sistema se va a utilizar la siguiente arquitectura y herramientas:
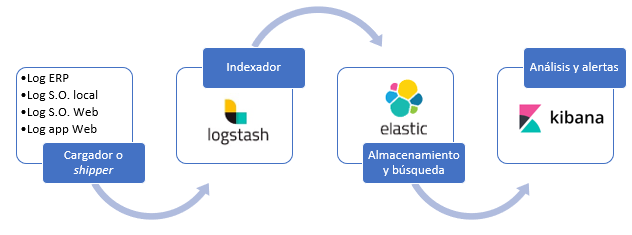
Las herramientas elegidas son de software libre y se engloban bajo la estructura Elastic Stack. Por lo tanto, la integración y convivencia de las herramientas va a ser total; disminuyendo así las necesidades de mantenimiento y maximizando las oportunidades de escalabilidad.
Tras haber definido la arquitectura del sistema, se deben realizar las siguientes actividades:
- Instalación y configuración de Logstash.
- Localización de logs de acceso y configuración del cargador en Logstash.
- Configuración de la transformación y normalización de los registros de log en Logstash.
- Instalación y configuración de ElasticSearch.
- Preparación de la la indexación de datos en ElasticSearch desde Logstash.
- Instalación y configuración de Kibana.
- Preparación de los informes y alertas necesarias en Kibana.
Una vez realizadas las tareas y al haber puesto el sistema en marcha, podrán empezar a visualizarse los primeros gráficos. Según se vaya obteniendo más volumen de datos, se podan ir realizando ajustes que permitan obtener mejores resultados. Del mismo modo, podrán añadirse nuevos logs así como integraciones con herramientas de terceros.
4. La gestión centralizada de logs
4.1. El uso actual
Una vez que hemos visto como construir una central de logs unificada, vamos a ver en detalle qué podemos esperar de la gestión centralizada de logs. A continuación, vemos algunos ejemplos prácticos:
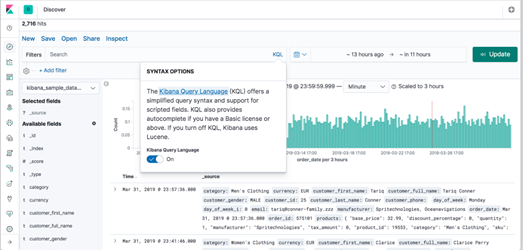
Ejecución de consultas específicas sobre los registros del log:
Utilizando los diferentes lenguajes o asistentes de consulta que contienen las herramientas de análisis, como Kibana Query Language[20], vamos a poder obtener de forma rápida información específica, por ejemplo: usuarios que han accedido a las aplicaciones de la empresa desde IPs o localizaciones diferentes a las permitidas.
Generación de nuevos indicadores a partir de valores existentes:
En Kibana, podemos generar nuevos campos, por ejemplo, un % de peligrosidad de un usuario en base a varios valores de los registros. Podría ser interesante generar una puntuación según el país, la hora de acceso, las acciones realizadas, etc. y así, poder darle una puntuación. Cuanto mayor sea la puntuación, mayor será el riesgo. De esta forma, podemos clasificar usuarios y posibles conductas indebidas.
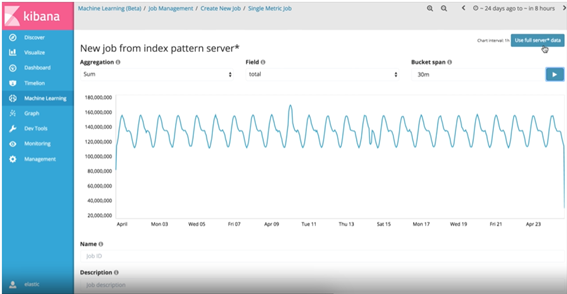
Detección de anomalías mediante el uso de aprendizaje automático:
Las funcionalidades integradas en XPack de Kibana facilitan la detección de anomalías mediante técnicas de Machine Learning. La herramienta es capaz de ir aprendiendo a partir de los datos que va recibiendo y, con el paso del tiempo, es capaz de saber si se está dando un comportamiento que no es el que debería con lo que ha aprendido. Por lo tanto, es muy útil, por ejemplo, para la detección de errores en las aplicaciones o sistemas informáticos en los que el comportamiento del usuario puede ser síntoma de que algo no está funcionando de la forma esperada.
Creación de alertas para casos que requieran de actuaciones inmediatas:
Como hemos visto, también es posible la puesta en marcha de alertas[21] que permitan avisar a responsables de los sistemas que existe un riesgo inminente y que puede requerir de una intervención inmediata. Por ejemplo, un usuario ha fallado 5 veces en su intento de acceder a una herramienta corporativa en los últimos 15 minutos y desde una misma IP. En ese mismo instante, el administrador de sistemas, si así se ha diseñado, podría recibir un mensaje de correo electrónico para que pueda ponerse en contacto con ese usuario y dar el soporte necesario.
Implementación de tareas automatizadas o acciones:
Por último, también en Kibana, es posible generar un tipo de alerta con Watcher[22] que actúe o lance una tarea y que proceda a una solución automática, por ejemplo, en el caso de detectar que una máquina está sufriendo un tipo de ataque orquestado o que tiene memoria o recursos insuficientes, podría lanzarse una alerta de tipo Webhook que llama a un servicio web para que reinicie la máquina o bloquee el ataque de intrusos.
4.2. Aplicaciones avanzadas y futuro
Como no podría ser de otra manera, el tratamiento de los datos para convertirlos en conocimiento de valor para las organizaciones pasa, en los casos más avanzados, por la aplicación de algoritmos matemáticos o la ciencia estadística, utilización de Big Data, redes neuronales artificiales[23] u otras herramientas de la Inteligencia Artificial que están por llegar.
Sin
ir más lejos, no sería de extrañar que en unos pocos años el análisis de los logs
de una compañía derive en la posibilidad de incluir la automatización de
futuras decisiones de compra (memorias, discos u otro hardware que se
estima dejará de funcionar pronto), la generación automática de líneas de
código (robots programadores) en base a nuevas necesidades detectadas o la
creación de bots de defensa que aprendan a realizar tareas avanzadas en
seguridad a partir de los datos obtenidos.
BIBLIOGRAFÍA:
[1] https://es.wikipedia.org/wiki/Syslogd
[2] https://en.wikipedia.org/wiki/ACID
[3] https://www.elastic.co/es/products/elasticsearch
[4] https://lucene.apache.org/solr/
[5] https://www.elastic.co/es/products/beats
[6] https://redis.io/topics/pubsub
[7] https://activemq.apache.org/
[8] https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern
[9] https://www.elastic.co/es/products/logstash
[11] https://www.graylog.org/products/open-source
[12] https://www.elastic.co/es/products/elasticsearch/features
[13] https://en.wikipedia.org/wiki/Kibana
[14] https://www.elastic.co/es/what-is/elasticsearch-alerting
[15] https://es.wikipedia.org/wiki/Grafana
[16] https://grafana.com/grafana/dashboards
[17] https://es.wikipedia.org/wiki/Cacti
[18] https://es.wikipedia.org/wiki/Splunk
[19] https://es.wikipedia.org/wiki/Datadog
[20] https://www.elastic.co/guide/en/kibana/master/kuery-query.html
[21] https://www.elastic.co/es/videos/watcher-lab-creating-your-first-alert
[22] https://www.elastic.co/guide/en/kibana/current/watcher-ui.html